… for the Shared cM tool …
For roughly the forty-‘leventh time in just the past few weeks, The Legal Genealogist answered a question the same way just a couple of days ago.
A Facebook poster couldn’t understand why a paper-trail third cousin once removed showed up as a DNA match with whom he shared 111 centiMorgans (cM) when a published chart the poster had been using said he should expect to share much less.
And my answer was the same as I’d given so many other times: put that chart away and use the Shared cM Project tool on DNA Painter instead.
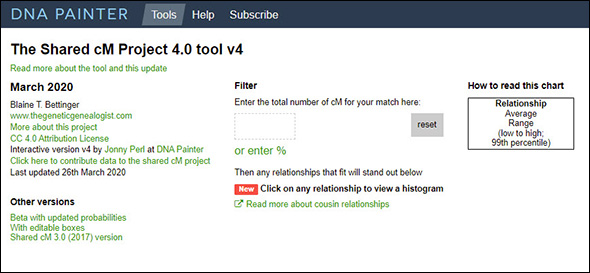
Why? Because all those published charts show the purely mathematical shared DNA amounts: we share 50% of our DNA with a parent or a child (or, on average, 3,400 cM); 25% with a grandchild or a grandparent or an aunt, uncle, niece or nephew (or, on average, 1,700 cM); 12.5% with a great-grandparent or a great-grandchild, a first cousin, a great-uncle, great-aunt, great-nephew or great-niece (or, on average, 850 cM); and so on with the amounts dropping by half for each generation as the relationships get more distant.1
Nice, neat, mathematical progression.
And, of course, real life isn’t nice or neat.
Taking a first cousin relationship, for example, where the chart tells us we should expect to share 850 cM of DNA, actual reported documented paper-trail cases tell us the amount we might share is going to be in a range from a low of 330 cM to a high of 1,486 cM, with the average being 865 cM.2
And how do we know that? Because one genetic genealogist — Blaine T. Bettinger, author of (among other things) The Genetic Genealogist blog — set out to collect real-world data, and has published and updated the data collected over a period of years. Called the Shared cM Project, it’s “a collaborative data collection and analysis project created to understand the ranges of shared centimorgans associated with various known relationships.” As of the last updated, in March 2020, citizen scientists had contributed data for nearly 60,000 known relationships.3
So… overdue thank-you number 1, to the thousands of citizen scientists who contributed that real-world data and to Blaine as the visionary who understood the value of collecting and analyzing that data.
Using that data, however, wasn’t quite so easy at first. Some of us who are … um … math-challenged, shall we say … struggled to apply it in our day-to-day research.
And then in 2017, Jonny Perl, developer of the DNA Painter website, recognizing that this was “an incredibly useful dataset that helps genealogists start to figure out just how they might be related to an unknown match,” went ahead to develop and release a web-based version in which we could enter a number — how much DNA we shared with a match in cM — and then filter the results visually.4
So… overdue thank-you number 2, to Jonny Perl who recognized not just the value of this data but also the difficulty faced by those math-challenged folks like me in using it, and produced a tool to give us easy access to it.
There still was a missing piece, however. The first version of the tool would highlight the possible relationships but it said nothing about how likely any possibility was. So entering 500 cM, for example, we could see that the match could be anything from a great-grandparent to a half first cousin once removed (with a lot of other options), but nothing that told us which possible relationship to look at first.
Enter Leah Larkin, who was already working with Jonny on DNA Painter‘s What Are the Odds tool, and a whole bunch of statistical analyses.5 Which, as of late in 2017, added probabilities to the Shared cM tool so that, now, entering 500 cM, we see that one set of possible relationships has a 90% chance of being right, while two other sets of possibilities have only a five percent chance.
So… overdue thank-you number 3, to Leah Larkin who is not just The DNA Geek but also a math geek — whose combination of those geeky skills added critically-needed qualifiers to this tool.
No, this tool alone won’t tell us that someone with whom we share 500 cM of DNA is a half first cousin rather than, say, a half great-niece or -nephew. But it does tell us to look at both of those first before we consider, say, a second cousin or first cousin twice removed.
And for that we all owe them all an overdue thank you!
Cite/link to this post: Judy G. Russell, “An overdue “thank you”,” The Legal Genealogist (https://www.legalgenealogist.com/blog : posted 5 Dec 2021).
SOURCES
- ISOGG Wiki (https://www.isogg.org/wiki), “Autosomal DNA statistics,” rev. 11 Nov 2021. ↩
- Blaine T. Bettinger, “Meiosis Groupings,” The Shared cM Project Version 4.0 (March 2020), The Genetic Genealogist (https://thegeneticgenealogist.com/ : accessed 5 Dec 2021), PDF at 7. ↩
- Ibid., The Shared cM Project Version 4.0 (March 2020), PDF at 1. ↩
- See generally Jonny Perl, “Introducing the updated shared cM tool,” DNA Painter blog, posted 27 Mar 2020 (https://blog.dnapainter.com/blog/ : accessed 5 Dec 2021). ↩
- See Leah Larkin, “The Limits of Predicting Relationships Using DNA,” The DNA Geek, posted 19 Dec 2016 (https://thednageek.com/ : accessed 5 Dec 2021). ↩


Yes, thanks to those wonderful people, and to a certain legal genealogist who tries very hard to keep us all on the straight and narrow.
Thanks for the kind words!
A thousand times THANK YOU to Blaine, Jonny, and Leah!
Amen to that. And as one of the contributors, you’re welcome. 🙂
Hello, Judy. I was reading your blog and fell upon this article. Your reference to Blaine T. Bettinger’s “Shared cM Project” caught my eye. His is not the only source for that type of data. Ancestry has a series of “white papers” where they provide similar information. A few years ago I called their tech support number because I was interested in additional statistics and suggested they add my suggestion to their reporting. (They did. More on that below.)
To begin with, I refer you to Ancestry’s, “AncestryDNA Matching White Paper” (Last updated July 15, 2020). Link:
https://www.ancestrycdn.com/support/us/2020/08/matchingwhitepaper.pdf (34 images)
There is also an earlier version (which is the one I read some time ago). It is longer. For completeness, I give you that link, as well. I will only cite the most recent version. The older version was “Last updated March 31, 2016.” Link (older version):
https://www.ancestry.com/corporate/sites/default/files/AncestryDNA-Matching-White-Paper.pdf (46 images)
The 2020 version, page 23 contains figure 5.2*. This figure shows, for the number of meiosis events separating two related individuals, what the probability distribution in cMs (cMorgs) looks like. This is similar to what Blaine’s Shared cM Project chart tells you. Ancestry’s depiction is derived from a number of perspectives. Here is a quoted passage summarizing their approach.
“To develop a method for accurately estimating relationships from IBD, we use genetic data from
thousands of pairs of individuals with known family relationships (either real people with
documented pedigrees or simulated individuals with known pedigrees). Additionally, we use
other information beyond IBD inferred from genetic data to ensure that our estimates of close
relationships—specifically, parent-child and sibling relationships—are as accurate as possible.
Methods for relationship estimation are detailed in section 5.” (page 6)
Naturally, the question arises as to which source, Blaine’s or Ancestry’s, gives the best predictions. I lean towards Ancestry for a number of reasons.
Ancestry has a massive number of cases in their DNA database. Blaine has relatively few. That means that Blaine has wider estimated cM ranges around his relationships (2nd cousin, 3rd great grandparent, etc.) and more overlap among them. [Editorial note: The following was intended as a numbered list. Formatting was lost when this document was posted]
Ancestry has loads of staff to vet the documented pedigrees that it receives. It’s unlikely that Blaine can vet the cases people voluntarily submit to him. He’s dependent on submitters’ accuracy.
Ancestry adds simulated cases. They can do this because they have professional geneticists that know how to model meiosis events. This means they can simulate a virtually unlimited number of cases to sharpen their estimated probability distributions.
Ancestry uses additional genetic knowledge to enhance their results even more.
Ancestry has big dollars, big staff, expansive genetic expertise to do the job about as well as it can be done.
Blaine gets credit for being the first one out in DNA genealogy space to provide the DNA information that his Shared cM Project addresses. That deserves recognition.
Earlier, I mentioned a suggestion that I made to Ancestry. Figure 5.2 shows the distribution of cM values for a given relationship: number of meioses, degrees of separation between two related individuals (matches). These are continuous distributions. Also of interest is the distribution that reverses the conditional probability. Instead of what’s the distribution of cMs given the number of meioses/degrees of separation, what is the likelihood of any relationship (number of meioses/degrees) given the number of cMs shared by a DNA match? This is a discrete distribution. For example, for a match sharing 80cM, what percentage of the time is that a second cousin, a third cousin once removed, a 2nd grandparent, etc.
This discrete distribution is available for each of your Ancestry matches. From the “view all matches” page, pick out the entry for any matching individual. Immediately to the right of that individual’s ID is the description of your relationship to him or her. Click on that relationship and a popup window will show all the probable relationships.
EXAMPLE:
Clicking on this particular relationship:
“3rd – 4th Cousin
80 cM | 1% shared DNA”
yields the following popup details
“Possible DNA relationships
This table shows the percentage of the time people sharing 80 cM have the following relationships:
Percent Relationship
39%
2nd cousin 1x removed
Half 2nd cousin
1st cousin 3x removed
Half 1st cousin 2x removed
34%
3rd cousin
2nd cousin 2x removed
Half 2nd cousin 1x removed
Half 1st cousin 3x removed
13%
3rd cousin 1x removed
Half 3rd cousin
Half 2nd cousin 2x removed
2nd cousin 3x removed
9%
2nd cousin
1st cousin 2x removed
Half 1st cousin 1x removed
Half great-grandaunt/granduncle
Half great-grandniece/grandnephew
3%
4th cousin
3rd cousin 2x removed
Half 3rd cousin 1x removed
Half 2nd cousin 3x removed
<1%
4th cousin 1x removed
Half 4th cousin
Half 3rd cousin 2x removed
3rd cousin 3x removed
<1%
5th cousin
4th cousin 2x removed
Half 4th cousin 1x removed
Half 3rd cousin 3x removed"
What if your match is not on Ancestry, but it's on some other DNA test provider's system? The preceding report (distribution) is a function of cMs. If you match someone on a different DNA test vendor's database, use the cMs from that other vendor and find any match with the same number of cMs on Ancestry. The Ancestry report will apply to the match on that other system.
———
*NOTE: Figure 5.2 assumes that both lines from the "closets common ancestor" (CCA) descend from full siblings. For the case where they were actually half-siblings, this would be the as if they descended as siblings from the pair of grandparents that they share. That is, there is effectively one more meiosis event between them.
I’m not going out of my way to thank a commercial testing company for doing the work needed to sell its product. What was done and continues to be done by Blaine and through the data contributions of the citizen-scientists behind Blaine’s project adds real world info that’s invaluable, and the free tool at DNA Painter (operative word: free) puts the power of that info into everyone’s hands. THAT earns my thanks.